What is SMASH?
SMASH is part of DFG Priority Program 2377 and is a joint initiative by the DBSE and ParCIO groups at Otto-von-Guericke-Universitat. The core objective of the project is to investigate the benefits of a common storage engine that manages a heterogeneous storage landscape, including traditional storage devices and non-volatile memory technologies. It aims to provide a prototypical standalone software library to be used by third-party projects. High-performance computing workflows will be supported through the integration of SMASH into the existing JULEA storage framework. Database systems will be able to use the interface of SMASH directly whenever data is stored or accessed.
Why SMASH?
Data is becoming increasingly important in science, and this is causing problems with how research is done. Since data is so important, more and more research is being done that requires a lot of data to be processed. This means that traditional systems used to manage data (like file systems and database management systems) are having a hard time keeping up with the flood of data. One problem is that traditional systems rely on different types of memory (primary, secondary, and tertiary) which can have very different performance characteristics. This makes it difficult to take advantage of the unique features of each type of memory. There are also some new technologies that can help with managing data, but they are still having a hard time dealing with the sheer amount of data that is being produced.
All of the proposed solutions to the memory problem have some drawbacks. One is that they are designed for the traditional memory hierarchy, which uses optimized block access for hard drives. This means that they may not be as effective when using other types of storage, such as NVRAM or NVMe, which have different benefits. Another drawback is that they only focus on one specific type of storage, like NVRAM or NVMe, which significantly limits the system’s overall capacity. However, there is a way to overcome these drawbacks and improve the performance of future data centers by incorporating all modern storage devices.
To help improve things, SMASH will use both old and new technology to create a more flexible system for storing files. This will help keep systems more compatible with existing applications, and help solve three major problems with the way things are currently done.
Inefficient use of complex memory and storage hierarchy: Modern systems employ hierarchical memory and storage stacks using a variety of memory and storage devices. Furthermore, the mixture of software and hardware caching creates additional complexity and makes it hard to understand when data is actually committed to persistent storage. However, it is still a challenging task to exploit the properties of all available storage devices without too much data shuffling.
Missing support for data transformations: Storage hardware continues to improve rapidly, but the improvement rates for SSDs are lagging behind. Even though SSDs provide a much higher throughput than HDDs, they suffer from similar problems, such as the inability to store and transfer data efficiently. Data compression and data distribution can help reduce this problem, but only a small number of database systems and file systems provide native support. In order to support data transformations, support needs to be built into the underlying data structures, since logical and physical offsets no longer always match.
Special-purpose solutions: The existing database management systems and file systems are not well-suited to adapting to changes in the data structures, and the kernel-based file systems are particularly difficult to use and expensive to evaluate. This hinders innovation in this area.
How SMASH works (a conception)?
SMASH aims to address the presented main issues by focusing on the following objectives:
Our team aims to design a storage engine that will make use of new technology to improve performance and solve inconsistency and heterogeneity problems in current systems. They will also use NVRAM to cache data, in the event of a crash or power loss. They will also use persistent long-term storage, such as NVMe and SATA SSDs, and different types of HDDs. Because NVRAM has higher latencies than traditional DRAM, they will have to take into account potential performance problems.
The team is investigating ways to natively support data transformations, as data volumes are becoming increasingly problematic. This is important as transformations can change data offsets, which can impact the accuracy of data storage. Additionally, modern storage hardware can be used to accelerate data transformations, which can help reduce the time it takes to process data.
We are developing a library that can be used for basic block allocation and management on top of memory and storage devices. This library will be integrated into selected database management systems and file systems, so that it can be used with a variety of applications. We will evaluate LevelDB and RocksDB, two popular storage libraries, to see how well our library works with them.
SMASH Architecture
SMASH’s architecture includes several components which allow for access to key-value and object data. These APIs will be used by high-level data management systems, such as database management systems and file systems. SMASH will be able to run existing HPC applications that make use of self-describing data formats with relatively little extra effort using the infrastructure already available in JULEA.
SMASH will provide convenient key-value and object interfaces to third-party projects, with the underlying Bϵ-tree spread across NVRAM and different types of SSDs and HDDs. DRAM will be used as a caching layer in either read-only or read-write mode, depending on the actual devices being used.
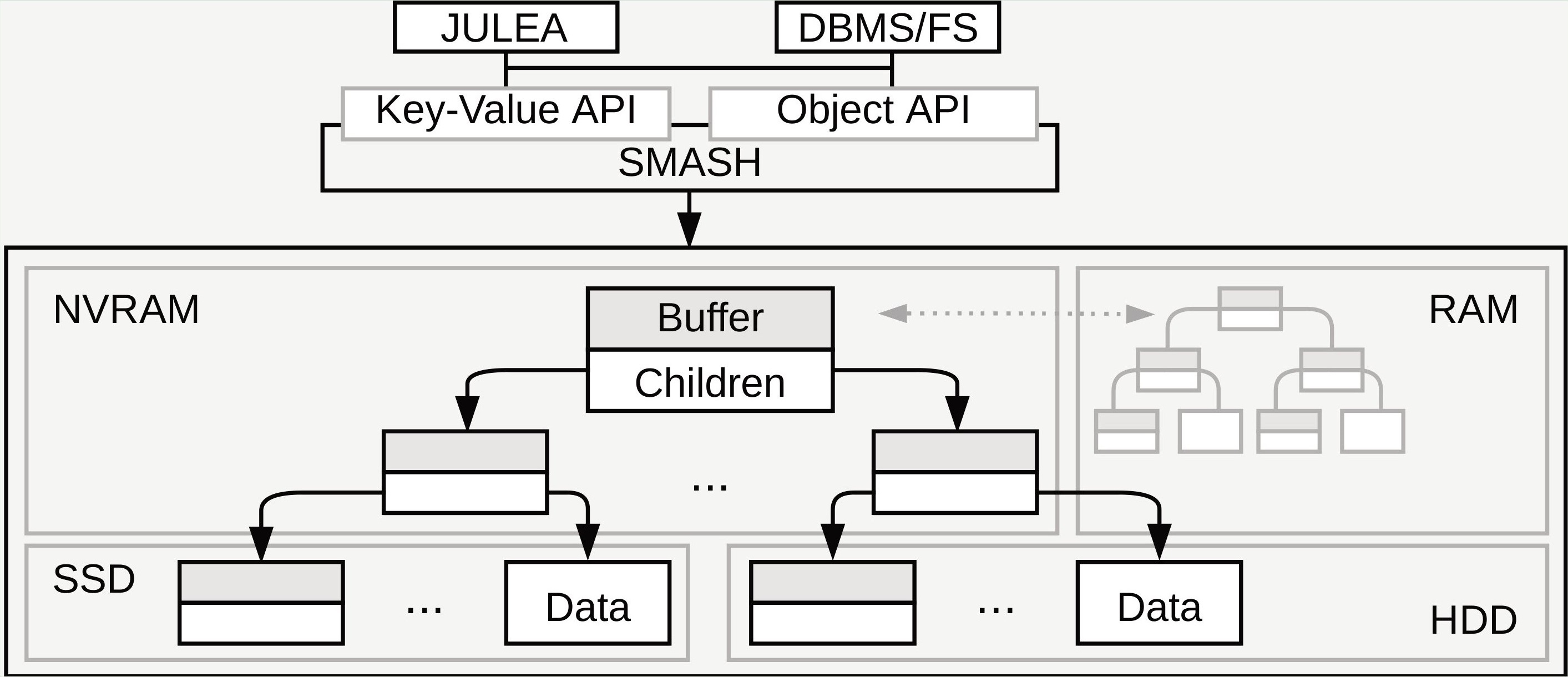
SMASH Components
Haura
Haura is a general-purpose and write-optimized tiered storage stack that runs in user space and supports object and key-value interfaces. It has the ability to handle multiple datasets, provides data integrity, and supports advanced features like snapshots, data placement, and fail-over strategies. The core of the engine is a B𝜖-tree which is the sole index structure in the engine. It supports block storage devices, solid-state drives, for instance, and also has the capability to use DRAM as a block storage device. It also offers features like data striping, mirroring, and parity. It was initially built as a key-value storage engine where arbitrary-sized keys and values can be stored.
Work In Progress (Recent Activities)
The team meets several times a month to discuss the project and its progress. The minutes of the meetings and the other related work, proposals to design and data structures, for instance, are recorded in different wiki pages under a Git project. Please check this link for more details.